Screenshots from the blog posts

Summary
How John the Ripper runs, on what platforms it runs, and what types of hashes it can handle.
Description
Intro
John The Ripper, or John for short, is one of the most well known password and hash cracking tools out there. John is extremely versatile, most importantly, it is extremely fast, with a really big range of compatible types of hashes, not just the most common ones like SHA1, SHA256, MD5, etc. It is also worth mentioning that John will work on all of the three most common operating systems – Windows, MacOS, and Linux-based distros. For Windows, there’s also the Hash Suite, developed by a John the Ripper Contributor.Hashes
Hashing, most simply put, is the act of taking a piece of data (of any length) and representing it in another shape, that is of fixed length. We do so by passing our original data through an algorithm – hashing algorithm. Some more popular examples are: NTLM, MD4, SHA512.As an example, take my name – acephale as an input string and pass it through a SHA256 algorithm, and we get the following string of characters:
b10a0dd841ddffef3c0e8aa683c7d9c97bdc048f8183ed41274e64e4faa3899d.
For watermelon, we get 31a2d5282683edb3a22c565f199aa96fb9ffb3107af35aad92ee1cd567cfc25d.
From this we can infer that we will always get an output of 64hexadecimal characters, or 32 bytes which is exactly 256 bits of data.
What makes them secure, and computationally impossible to reverse, is the underlying mathematical (cryptographic) background, at the core of the concept, known as the P vs NP problem. To explain this we would need a mathematician, specifically a cryptographer; nevertheless, the basic idea is that the hash algorithm is intended to operate one way only. We can’t use the calculated hash value – output, to reverse the hash value. Luckily, it's enough to determine the hashing algorithm that was used (this would be the NP part of the P vs NP problem), and compare that hashed value against the hash of the same input that we have previously calculated using the same algorithm, and check to see if they are equivalent.
This is what John leverages to identify the hashes when using a dictionary type attacks, when going through a given list and hashing the words inside it so that it can compare it to our target password.
Uses and Attack Types
With John you can also crack Windows Authentication Hashes, /etc/shadow/ hashes, password protected .zip and .rar archives, as well as SSH keys. The most commonly used attack type is dictionary attack, which we use to brute force the target password. However, John also offers Single crack mode and custom rules.Let’s quickly take a look at some common attack types and techniques.
Dictionary Attack
The dictionary attack utilizes wordlists to have a go at our target password. A wordlist is just a file with a list of words inside, that we give to John to hash and compare against our target password. You can find a lot of great wordlists out there, for example here. Also, if you have Kali or ParrotOS machines running, you can find wordlists by default in the /usr/share/wordlists directory.Rainbow Attack
Rainbow attack is an attack method where we use a so-called ‘rainbow table’ to cache the outputs of the cryptographic hash functions. Similar to wordlists, in a rainbow table we would have the plaintext of the hash in one column, and the hash in the other. Then, we can just look for the corresponding hash in one column and return its plaintext value.With rainbow attack we don’t have to hash every possible word and compare, we basically just do a lookup which is much quicker, however, note that we still have to pre-compute all the values in our table.
Brute Force
A brute force attack, as the name implies, is a trial and error type attack where we try to guess possible password combinations by going through all the possible variations. This method is good for shorter passwords and can quickly crack them, but for longer passwords you’re much better off with a dictionary type attack, as the brute force method quickly becomes computationally infeasible to use.One great example of the relationship between complexity and time needed to crack the passwords can be found here.
Basic Syntax and Uses – Examples
John has features built into it that can detect the type of hash that we have supplied it with, and it can try applying the needed rules to crack it. This is not always ideal, but if we are in a hurry, and just want to try and crack the hash quickly, it might be useful. We do so by specifying:john --wordlist=[path_to_wordlist] [path_to_target_hash]
Wordlist – this parameter tells John that we want to use a wordlist, and where it can find it
path_to_target_hash – this is the location where our target file with the hash inside can be found
An example command would be:
john --wordlist=/usr/share/wordlists/rockyou.txt target_hash.txt
Generally, to specify a command for John, we use the following syntax:
john [option] [path_to_file]
Where option parameter is used to tell John what we would like to do.
To specify an exact format, once we’ve identified the hash successfully, we can give a following command to john:
john --format=raw-sha256 --wordlist=/usr/share/wordlist/rockyou.txt target_hash.txt
Examples
To further illustrate some of the basic options that we’ve discussed, let’s give a couple of quick examples.
We have a .zip file of hashes that we want to crack, which we’ve extracted:
Inside the hash1.txt is a hash we already are familiar with 31a2d5282683edb3a22c565f199aa96fb9ffb3107af35aad92ee1cd567cfc25d – watermelon, and we've given it to John below, only specifying the default rockyou.txt wordlist, and in turn John gives us some suggestions as to what hashing algorithm was used for this hash.
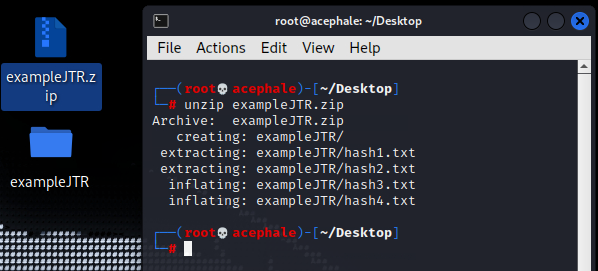
As we can see in the screenshot above, John isn’t quite sure, but that’s okay. Not because we already know that it is SHA256 that we’re looking at, but because we can easily verify this using many of the available tools online. One great hash-identifying script you can find online is this Python script. You can easily pull it from Gitlab with wget, and run it with python3 hash-id.py.
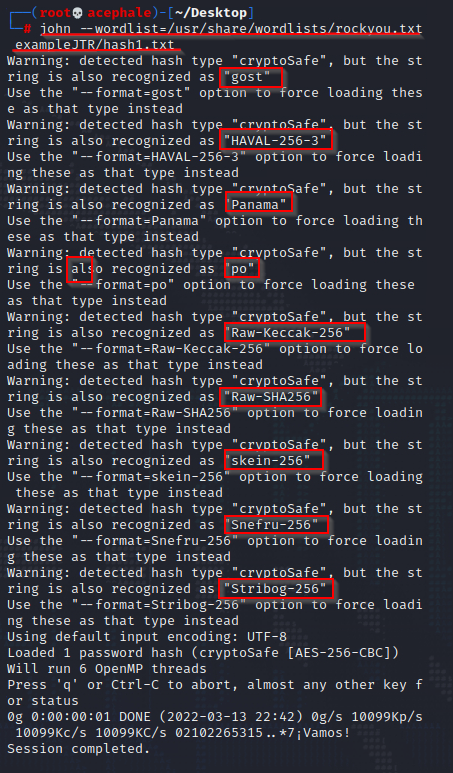
Since we know our hash in question is SHA256, we specify that to John and supply it with the rockyou.txt wordlist hoping it got us covered (after all there’s 14344392 lines in the file).

Et voila! John has cracked the password, and as we can see from the image, in yellow font, it gives us the password – watermelon. When we add the –show option that John tells us about below, we get the following output.
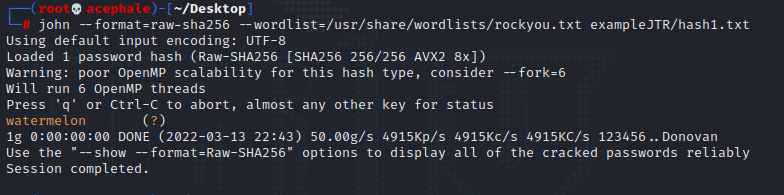
And that’s pretty much it. To practice a bit more, let’s try and do the other examples.

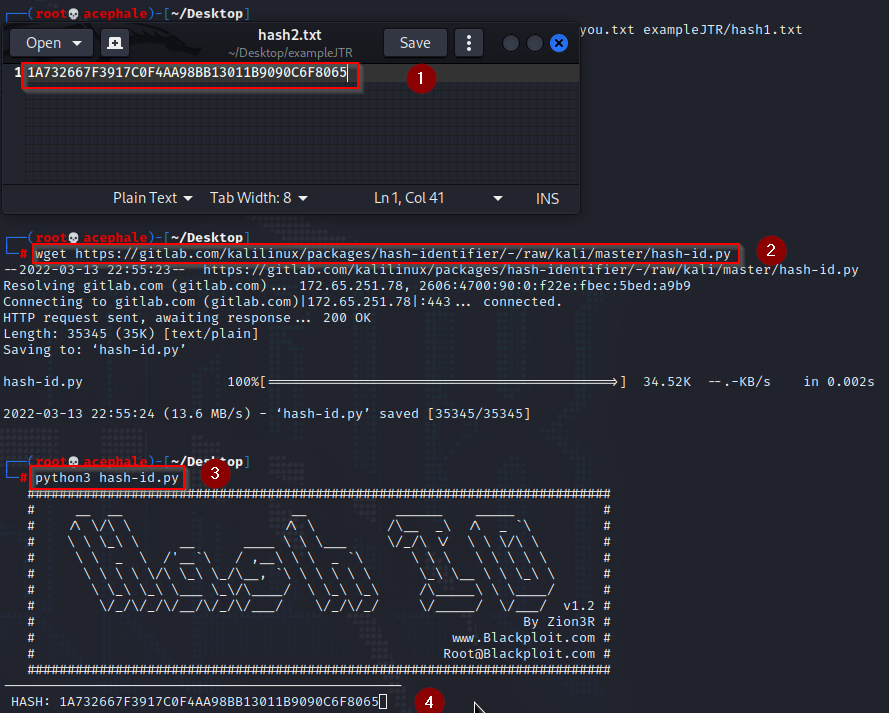
We used wget to download a hash identifier tool from Gitlab (2), copied the hash to our clipboard (1), started the hash-id.py tool (3), and pasted in the hash we wanted to identify (4). The results are:
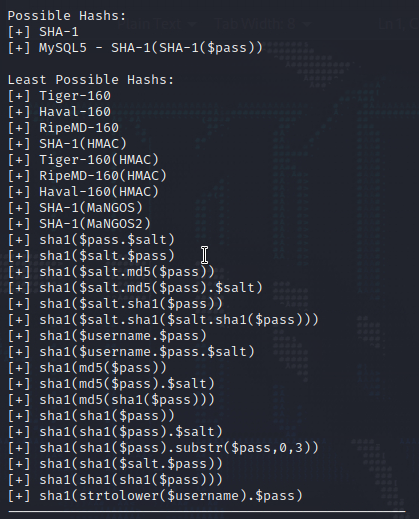
From this, we can infer that our target hash is most likely SHA1 hash, which we will tell John to check against, using our wordlist. We do the same as before, and we quickly obtain the cracked password.
For our third hash – hash3.txt we run the identifier tool first:
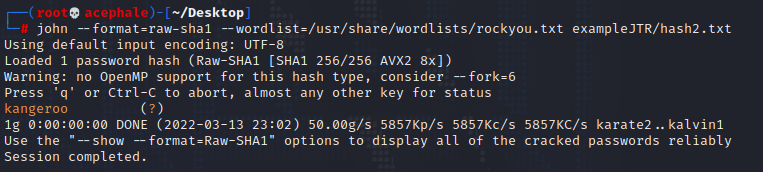
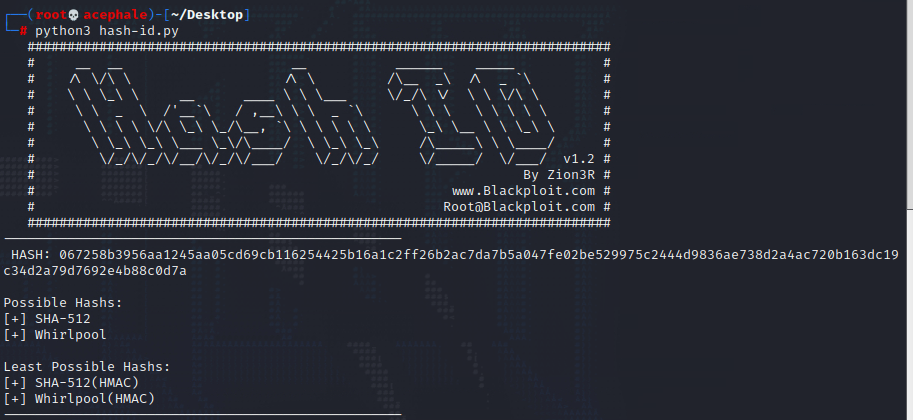
If we look a bit more closer, we can easily notice the length of this hash, and the possible hash output verifies that saying we’re dealing with a SHA512 hash, as the length of this hash is double (64 bytes) of SHA256, hence 512 bits – SHA512.
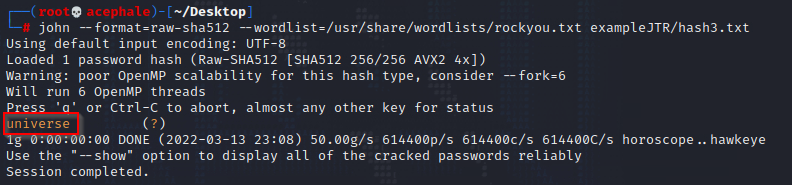
We specify the format to John:
And we get our hash.
Lastly, for hash4.txt, we do the same:
(hash4.txt - 1df4839a4177d33fd7010baba7d45d3b)
John has again given us a lot of options, so we try our Python tool.
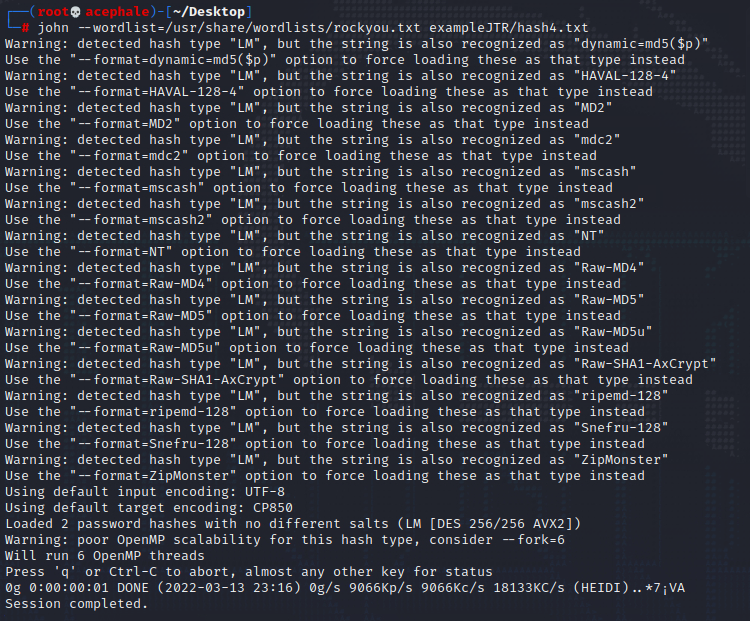
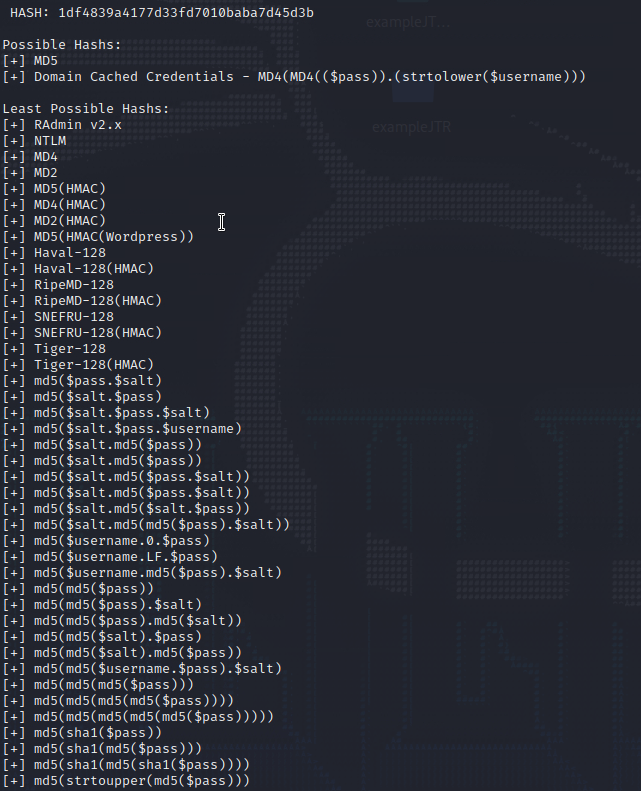
As we can see from the output, hash-id.py thinks its most likely to be MD5 or MD4 hash.
Let’s check for MD5.

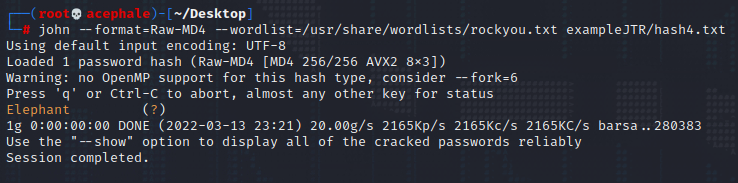
The output above is John informing us that it didn’t find a corresponding MD5 hash within the wordlist we specified. Let’s try the MD4 then.
{kind=link}
As we can see, it was indeed MD4 type hash, and our password is – Elephant.
Conclusion
To quickly summarize what we’ve talked about so far: we’ve touched on how John the Ripper runs, on what platforms it runs, and we’ve mentioned what types of hashes it can handle. There’s a lot more to it, and in real world scenarios we can’t expect things to go so smoothly as it did in our examples.In future articles we hope to cover Windows authentication hashes, cracking /etc/shadow hashes, single crack mode, custom rules, cracking password protected .zip and .rar archives, and cracking ssh keys, which we mentioned at the beginning of the article.